목차
- 연산
- 산술연산자
- 비교연산자
- bool연산자
- 삼항연산자
- 데이터형 변환
- 데이터 구조
- 리스트/튜플/딕셔너리
- 리스트안의 리스트(튜플안의 튜플)
- 리스트 내포 표기(List comprehension)
- 제어문
- if문
- for문
- while문
- range
- break/continue
- 함수
- 함수정의하기
- 람다함수
** 2021.01.20 일부 오타수정, 리스트 관련 함수 추가
1. 연산
[목차로 이동]
1. 산술연산자
| 기호/함수 | 내용 | 예시 |
| + | 덧셈 | - |
| - | 뺄셈 | - |
| * | 곱셈 | - |
| / | 나눗셈(소수점이 붙음) | 7 / 4 #1.75 |
| % | 나눗셈의 나머지 | 7 % 3 #1 |
| // | 나눗셈의 몫 | 7 // 3 #2 |
| ** | 지수 | 7 ** 4 #2401 |
| divmod(a, b) | a를 b로 나눈 몫과 나머지 반환 | divmod(7,4) #(1,3) |
2. 비교연산자
| 연산자 | 내용 |
| A == B | 두 개의 값이 같을 때 True 반환 |
| A != B | 두 개의 값이 같지 않을 때 True를 반환 |
| A < B | A가 B보다 작을 때 True를 반환 |
| A <= B | A가 B 이하일 때 True를 반환 |
| A in B | A가 B(리스트, 튜플)에 있을 때 True 반환 |
3. bool연산자
| bool연산자 | 내용 |
| 조건식1 and 조건식2 | 조건식1과 조건식2가 모두 True일 때 True 반환 |
| 조건식1 or 조건식2 | 조건식1과 조건식2 중 하나가 True일 때 True 반환 |
| not 조건식1 | 조건식1과 반대 bool값을 반환 (만약 조건식1이 True이면 False를 반환) |
4. 삼항연산자

a=5
x="True" if a>0 else "False"
# a가 0보다 크면(a>0, 조건식) x는 'True'
2. 데이터형 변환
[목차로 이동]
| 함수 | 내용 | 예시 |
| type( ) | 데이터형을 반환 | type(2.7) #<class 'float'> a = "asdf" type(a) #<class 'str'> |
| int( ) | 부동소수점형값(소수점 있는 수), 문자열, bool값을 정수로 변환 |
int(2.6) #2 int(True) #1 int(False) #0 |
| float( ) | 수, bool값, 문자열을 부동소수점형값(소수점 있는 수)으로 변환 * 변환 할 수 없는 문자열의 경우 오류 발생 |
float("2.12") #2.12 floast(True) #1.0 floast(False) #0.0 |
| str( ) | 수, bool값을 문자열로 변환 | str(7) #'7' str(True) #'True' |
| bool( ) | 수, 문자열을 bool값으로 변환 * 0, 0.0, "" 을 제외한 값을 전부 True로 처리 |
bool(3) #True bool('') #False |
3. 데이터 구조
[목차로 이동]
1. 데이터구조-리스트/튜플/딕셔너리
* 데이터구조에 담겨있는 요소에 접근할 때, 필요한 번호는 0부터 시작함
| 데이터 구조 | 설명 | 예시 |
| 리스트 [ ] | 다른 프로그래밍 언어의 배열이라고 생각하면 되며, 요소를 추가, 삭제, 수정 가능(mutable) |
lang_list = ['python', 'java', 'c] |
| 튜플 ( ) | 리스트와 유사하나, 튜플을 생성하면 변경할 수 없음(immutable) * 리스트에 비해 소비하는 메모리가 적다 |
lang_tuple = ('python', 'java', 'c') |
| 딕셔너리 { } | key와 value를 갖으며, key 값으로 value에 접근한다 |
twice = { "사나" : "일본", "미나" : "일본", "모모" : "일본", "쯔위" : "대만" } twice["미나"] #일본 |
| 리스트 관련 함수 | ||
| append( ) | 리스트 맨 끝에 요소를 추가 | list = ['a', 'b', 'c'] list.append('d') list #['a', 'b', 'c', 'd'] |
| insert( ) | 리스트의 원하는 위치에 요소를 추가 | list = ['a', 'b', 'c'] list.insert(1, 'B') list #['a', 'B', 'b', 'c'] |
| del list_name( ) | 리스트의 특정 요소를 삭제 * 삭제 대상이 리스트만 있는게 아니기 때문에 append, insert 와는 다르게 리스트의 이름을 사용 |
list = ['a', 'b', 'c'] del list[1] list #['a', 'c'] |
| remove() | 인수로 들어 온 값을 리스트에서 검색해 제일 앞의 일치된 값을 삭제 |
list = ['a', 'b', 'c', 'a'] list.remove('a') list #['b', 'c', 'a'] |
| clear( ) | 리스트 내의 모든 요소를 삭제 | list = ['a', 'b', 'c'] list.clear() list #[ ] |
| pop( ) | 지정한 위치의 값을 삭제하고 삭제한 값을 반환 |
list = ['a', 'b', 'c'] pop_list = list.pop(1) pop_list #b list #['a', 'c'] |
| copy( ) | 리스트를 복제 할 때 사용한다. | list_origin = [1, 2, 3] list_copy = list.copy() list_origin[2] = 4 list_origin #[1, 2, 4] list_copy #[1, 2, 3] * copy()로 list_origin을 복제했기 때문에 list_origin[2] = 4를 해도 list_copy는 바뀌지 않게 된다. 이유는 list_origin을 copy()한 시점에서 복제가 끝났고 list_copy는 list_origin과 다른값을 참조하기 때문 |
| sorted( ) | 인수로 주어진 리스트, 튜플을 정렬해 복사본을 반환(원본의 순서는 바뀌지 않음) 수치의 경우 오름차순, 문자의 경우 알파벳 순으로 정렬 |
origin=['c','a','b'] sorted(origin) #['a','b','c'] origin #['c','a','b'] |
| sort( ) | 원본 리스트를 정렬하며 반환값 없음 | origin=['c','a','b'] origin.sort( ) origin #['a','b','c'] |
| 리스트 튜플 관련 함수 | ||
| len( ) | 리스트, 튜플에 포함되는 요소의 수를 반환 * 인수의 리스트안의 리스트 구조를 넣으면 바깥쪽 리스트 항목 수를 반환 |
warrior = ('팔라딘','히어로','다크나이트') |
| in | 어떤 값이 리스트, 튜플에 포함되어 있는지 확인할 때 사용하며 True, False를 반환한다 |
warrior = ('팔라딘','히어로','다크나이트') '히어로' in warrior #True |
| index( ) | 어떤 값이 리스트, 튜플에 단순히 포함되어 있는지가 아니라 몇번째에 있는지 확인 하고 싶을 때 사용 |
warrior = ('팔라딘','히어로','다크나이트') |
| map( ) | map(처리함수, 리스트or튜플) * 리스트나 튜플의 요소가 처리하는 함수에 인자로 전달돼 처리한 후 map객체로 반환 * 객체로 부터 list를 만들기 위해서는 list() 함수를 사용 |
list(map(lamda x : x*2, [1,2,3])) |
| filter( ) | filter(요소를 고르는 함수, 배열) * 조건을 만족하는 요소만을 추출할 때 사용 * 어떤 요소를 걸러낼 함수를 만들 때는 람다식이 적합함 |
list(filter(lamda a : a%2==0, [0,1,2,3,4,5])) |
2. 리스트안의 리스트(튜플안의 튜플)
* 파이썬에서는 리스트안의 리스트(튜플안의 튜플)를 사용해 자바에서와 같은 다차원 배열 데이터 구조를 표현

warrior = ('팔라딘','히어로','다크나이트')
magician = ('아크메이지(불독)','아크메이지(썬콜)','비숍')
archer = ('신궁','보우마스터')
job = (warrior, magician, archer)
print(job[0][0]) #팔라딘
* 메이플스토리 초보자가 전직할 수 있는 직업 중 일부를 예시로 가져왔다. job 튜플 안에 warrior, magician, archer 직업 군이 각각 있으며,
' job[0][0] #팔라딘, job[1][0] #불독, job[2][0] #신궁 ' 와 같은 문법으로 각각 데이터에 접근 할 수 있다. 이와 같은 데이터 구조를 표현하는 방법은 튜플과 리스트에서 같다.
3. 리스트 내포 표기(List comprehension)
[식 for 요소이름 in 리스트이름]
[식 for 요소이름 in 리스트이름 if 조건식]
[x*2 for x in [1,2,3,4]]
#[2, 4, 6, 8]
[x for x in [0,1,2,3,4,5] if x%2==0]
#[0, 2, 4]
4. 제어문
[목차로 이동]
1. if 문
*조건식에 0, "",[#비어있는 리스트], (#비어있는 튜플) 은 False로 해석



2. for문
take_here = (0, 10, 20)
total = 0
for save_var in take_here :
total += save_var
print(total) #30* for save_var in take_here 에서 take_here 자리에 있는 리스트, 튜플의 값을 하나씩 꺼내 save_var에 저장
* save_var에 저장된 값을 갖고 for문 안에 있는 명령문을 실행
* 리스트, 튜플이 아닌 번호를 사용해하는 상황이라면 range를 사용함
* 리스트, 튜플, 숫자 뿐 아니라 문자열도 사용할 수 있음( for letter in "hi!" : print(letter) # h i !)
3. while문
* 조건식이 True인 동안, 정해진 루프를 계속 반복한다. 조건식이 False가 되면 루프를 빠져나와 다음 명령을 실행
* 루프를 빠져나오기 위해 사이클 당 증감하는 변수를 넣어 제어한다.

cnt = 0
while cnt<3:
print(cnt)
cnt +=1 #루프를 빠져나오기 위한 제어문
# 0 1 2
4. range
* 인수로 받은 숫자를 조건에 받게 반환
| range 유형 | 설명 | 예시 |
| range(최댓값) | 0부터 1씩 증가하고 최댓값 전까지 | for index in range(5); print(index) # 0 1 2 3 4 |
| range(시작값, 최댓값) | 시작값부터 1씩 증가하고 최대값 전까지 | for index in range(3, 7); print(index) # 3 4 5 6 |
| range(시작값, 최댓값, 스탭) | 시작값부터 스텝만큼 증가하고 최대값 전까지 | for index in range(1, 8, 2); print(index) # 1, 3, 5, 7 |
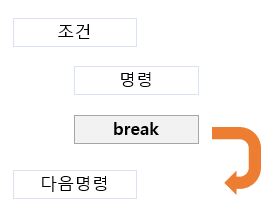
5. break/continue
* while, for 등 반복문을 벗어날 때 사용
* break는 루프를 벗어나 다음 명령으로 이동
* continue는 루프의 나머지를 건너 뛰고, 루프의 맨 앞으로 되돌아갈 때 사용

5. 함수
1. 함수 정의하기

* 원하는 함수를 위와 같은 형식으로 정의해서 사용할 수 있으며, 파라미터가 없을 때는 함수명 뒤 파라미터를 생략하고, 반환값이 없을 때는 return을 생략할 수 있음
2. 람다함수

* 람다 함수는 def로 정의하는 함수와 다르게 일회성 함수라는 성질이 강함
* 주로 map, filter, sorted 등과 같이 사용됨
check_even = lamda x : x%2 ==0
checnk_even(2)
#True
list(map(lamda x : x*2, [1,2,3]))
# [2, 4, 6]
list(filter(lamda a : a%2==0, [0,1,2,3,4,5]))
# [0, 2, 4]
sorted(['bc','a','def'], key=lamda x : len(x))
#['a', 'bc', 'def']
sorted(['bc','a','def'], key=lamda x : len(x), reverse=True)
#['def', 'bc', 'a']
** 그 외 함수
| 함수 | 설명 | 예시 |
| max(a, b) | a와 b 중 큰 값을 반환 | max(2, 6) #6 |
| min(a, b) | a와 b 중 작은 값을 반환 | min(2, 6) #2 |
'# Programming Language > Python' 카테고리의 다른 글
| [Python] 파이썬 정리(2)_iterator/컴프리헨션/람다/map/filter (0) | 2021.03.23 |
|---|---|
| [Python] 파이썬 정리(1)_얕은 복사와 깊은 복사 (0) | 2021.03.22 |
| [Python] 파이썬 게임 라이브러리_PyGame 도형그리기 (0) | 2021.01.19 |
| [Python] 파이썬 게임 라이브러리_PyGame 설명과 다운(파이참) (0) | 2021.01.19 |
| [Python] 파이썬&비주얼스튜디오 설치 (0) | 2021.01.15 |